Introduction
Datasaur and Snorkel are two of the industry-leading data annotation platforms when it comes to NLP-focused labeling automation at scale. However, the differences start to emerge when you look at how each platform is built, and how that foundation caters to fundamentally different use cases and workflows. This page will help you understand the difference between Datasaur and Snorkel so you can choose the right annotation platform for your team’s needs.
What does Datasaur do?
Datasaur helps machine learning teams better manage their labeling workforce and improve the quality of their training data. Its software comes with automated labeling and workforce management features, giving teams the tools they need to generate higher quality data, greater visibility into productivity, and significant cost savings. Datasaur was built for both the annotator and data scientist, which means the interface is designed to be intuitive for non-technical users, while file transformers and APIs make integration a cinch for data scientists.
What does Snorkel do?
Snorkel is a data-centric AI platform for automated data labeling, integrated model training and analysis, and enhanced domain expert collaboration. Built by the same team behind the Snorkel open-source library, Snorkel Flow extends the annotation capabilities to a platform designed for data scientists.
Key Functions of an NLP Annotation Platform
- Efficient Annotation: The platform has a user-friendly interface enhanced by AI-powered and assisted labeling, resulting in automated annotation processes with robust quality control measures.
- Integrated Workflow: The platform facilitates fluid workflows from the initial data source through to the annotated data for the subsequent training process, seamlessly connecting the pieces of the entire data life cycle.
- Workforce Management: The platform consists of advanced features surrounding user roles, permissions, and other technical functionalities to ensure collaboration among annotators and data scientists.
Capabilities
Annotation automation
Snorkel
- Snorkel emphasizes the application of weak supervision techniques within its data labeling processes. It empowers users to define custom labeling functions tailored to their specific use cases.
- Snorkel Flow allows the user to combine pre- and post-processing operators, models, and business logic, fostering a dynamic workflow experimentation environment, where users can iterate and optimize their processes effectively.
- Snorkel integrates active learning to pinpoint data segments of significant importance.
Datasaur
- Datasaur elevates weak supervision capabilities beyond the original open-source library. While the library is confined to text classification, Datasaur broadens its horizons by enabling data programming and labeling functions to annotate text spans.
- Datasaur seamlessly integrates with native or third-party models, incorporating popular open-source libraries like spaCy, NLTK, and Hugging Face and facilitating pre-labeling of substantial document portions.
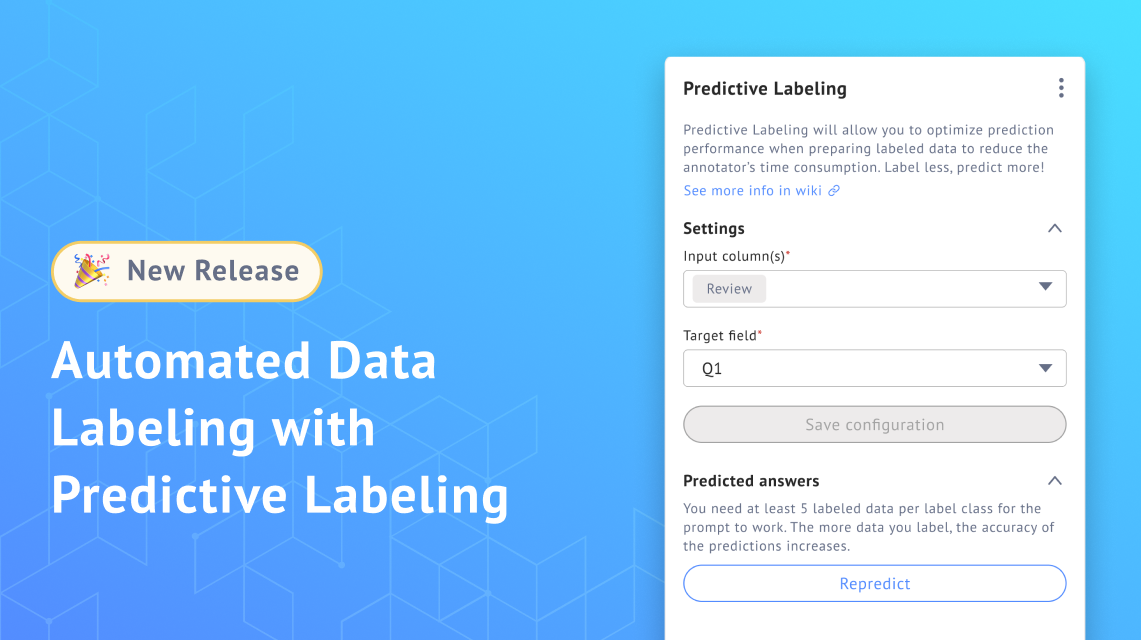
- By leveraging Language Model Models (LLMs), Datasaur automates the labeling process through predictive labeling, drawing insights from a small data subset to prepare an extensive dataset.
- Datasaur's automated pipeline workflow, from the creation of initial tasks to the final export stage, is powered by the innovative Datasaur Actions feature. This feature empowers users to precisely define the sequence of steps undertaken for each annotation requirement and reduce redundant processes. By offering granular control over the annotation workflow, Datasaur Actions not only optimizes efficiency but also ensures a tailored and meticulous approach to data labeling.
Data Quality Enhancement
Snorkel
- Snorkel takes a holistic approach to enhancing data quality by conducting comprehensive error analysis. This process identifies data segments that demand improvement, thereby determining ground truth and guiding refinements in the annotation process.
- An analytics dashboard helps in assessing model performance with respect to specific input data, enabling data-driven refinements.
Datasaur
- Datasaur offers a powerful dashboard of metrics measuring quality and efficiency, allowing project managers to understand high level project progress at a glance.
- The platform automatically calculates the inter-annotator agreement (IAA), providing insights into annotator consistency and highlighting who could use more training and who is ready to be promoted to the reviewer role. Notably, this IAA score can encompass both human and automated labeling, allowing users to assess a variety of automation techniques.
- Datasaur goes a step further by implementing automated peer-review as part of its validation process. Reviewers can then precisely locate and validate data segments in need of attention and enhancement.
Workforce management
Snorkel
- Snorkel's platform targets cross-functional collaboration between domain experts, annotators, and data scientists.
- The comments and tags feature allows data scientists to refine labeling functions and subject-matter experts (SMEs) to contribute domain-specific insights.
Datasaur
- Datasaur offers collaboration by granting specific and unique access privileges to data annotators, SMEs, data scientists and administrators. This approach enables each role to specialize in their distinct tasks, with annotators and SMEs focusing on data annotation and data scientists and administrators overseeing the overall workflow dynamics and data output quality.
- Automated peer review enhances data validation and QA by pinpointing areas that require refinement.
- Collaborative commenting functionality enables interaction among team members, particularly between annotators and data scientists, to maintain precision and accuracy.
- Datasaur's analytics offer insights on team goals, helping to track productivity and work toward maximum efficiency.
Workflow Integration
Snorkel
- Pipeline adjustment allows data scientists to fine-tune their experiments, integrating data and model-building seamlessly.
- Snorkel offers specific formats for data import and export, ensuring compatibility with standardized processes.
Datasaur
- Datasaur makes adoption easy by supporting multiple formats and providing customizable options. It also supports effortless import and export processes tailored to user specifications.
- For a frictionless model training journey, Datasaur enables users to integrate their own external object storage when creating projects. The platform seamlessly fits into your existing machine-learning pipeline, ensuring continuity and eliminating the need to switch between applications.
- Datasaur extends beyond text to text-adjacent areas, supporting audio, document and image annotation.
Ease of use and adoption
Snorkel
Snorkel is tailored for data scientists and engineers, offering flexibility for experimentation in labeling functions and model development.
Datasaur
- Datasaur focuses on user experience for all involved parties. Annotators benefit from intuitive features, while data scientists and engineers delve into advanced functionalities such as the code editor, custom scripts, labeling functions, and seamless integration with object storage or APIs.
- Datasaur's commitment to an ideal user experience is supported by dedicated customer support services available around the clock.
Scale and customization
Snorkel
- Snorkel offers diverse deployment options, spanning major cloud platforms like AWS, Azure, and Google Cloud, enabling users to select the environment that aligns with their infrastructure preferences.
- The availability of APIs and SDKs enhances flexibility for engineers and data scientists, facilitating customization of workflows to suit specific project requirements.
Datasaur
- Datasaur also supports major cloud platforms like AWS, Azure, and Google Cloud while tailoring custom deployment solutions to meet unique organizational needs. For example, financial and legal companies may require a fully on-premise deployment to meet stringent data protocols.
- Datasaur offers a file transformer feature that facilitates the effortless import and export of all types of data, saving data scientists pre- and post-processing work.
- Transitioning to new tools can be arduous, but Datasaur offers a smooth migration path. Users can integrate existing models, scripts, and data into the Datasaur ecosystem, optimizing workflow efficiency while maintaining continuity.