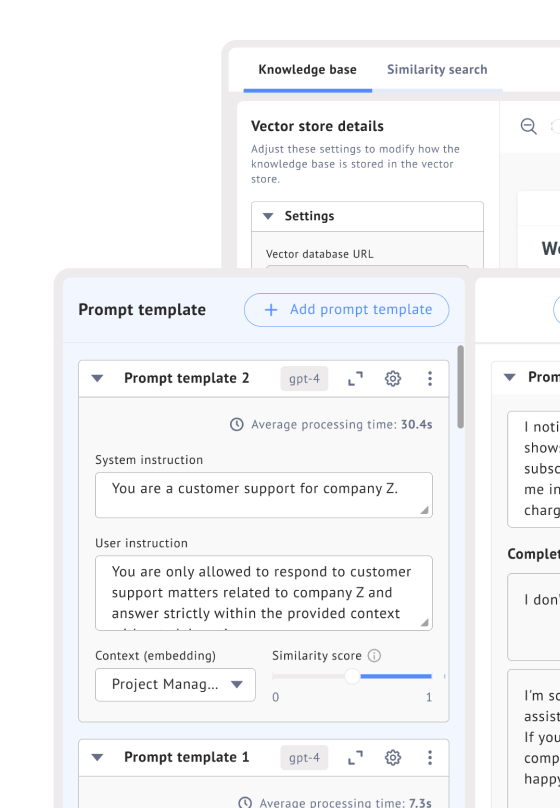
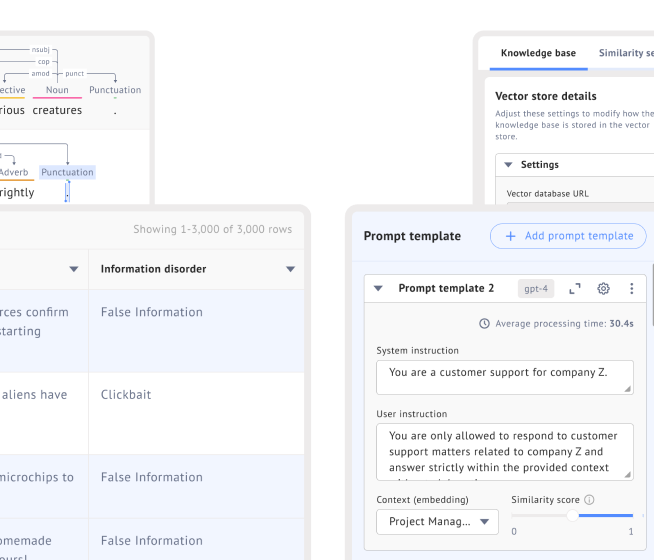
By providing context within your LLM that is specific to your area of knowledge, it can generate completions that are more relevant and accurate.
Example use case:
Automated customer support
Build, test, and iterate your LLM any time
Adjust your prompt template and parameters, test several existing models, deploy your LLM, and access your model via API endpoints.
Example use case:
Chatbots and virtual assistants
Rate and evaluate the responses to your prompts to align with your preference
With LLM Evaluation, you can rate and fine-tune completion for various prompts using a 5-star rating system. This process allows you to evaluate your LLM performance, rephrase the completions, and use the data to customize your LLM tone of voice.
Example use case:
Content generation
Enhance the results by ranking answer options for a prompt
With LLM Ranking, you can arrange the provided completions for a prompt based on your preferences. This process helps the model identify the best answers and enhance the quality of responses.
Example use case:
Question answering
Wondering how we can support your use case?
Contact us or schedule a scoping session with our sales and see how Datasaur can be applied to your labeling projects.
Say goodbye to labeling hassles! Datasaur streamlines NLP & LLM projects, saving your time and boosting productivity. Start your free trial for our product now!