We Tested 4 Top LLMs for Labeling. One Surprised Us.
Introduction
We tested four of the most popular LLMs on an entity labeling task to see which performs best out-of-the-box. This benchmark used Datasaur’s Labeling Agent feature to apply each model in zero-shot conditions. Our goal was to discover:
Method
We used 500 lines of text from the public WNUT-17 dataset, which contains user-generated content such as tweets. These are messy, short-form sentences, which makes them a good challenge for real-world entity recognition. The dataset is full of lingo and cultural references that challenge labelers with ambiguity.
The task involved labeling 6 entity types within the document: people, organizations, locations, products and creative works. We used a zero-shot prompt — no examples were provided — asking the model to extract entities from a given text into a structured JSON format.
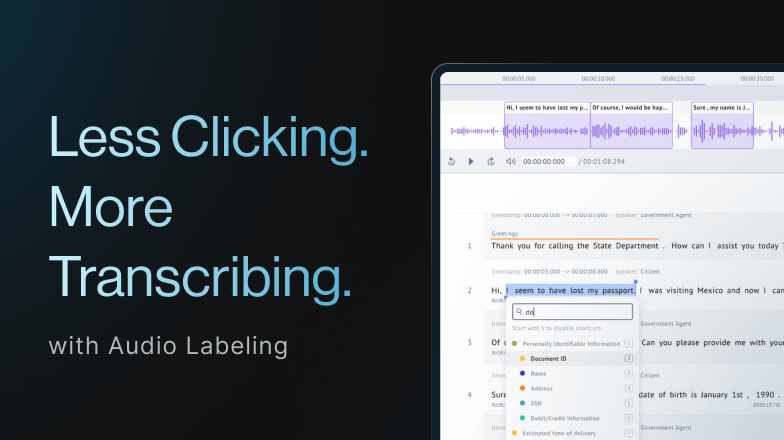
What is the Labeling Agent?
Labeling Agent enables teams to assign multiple LLMs as labelers to automatically label a project. It provides structured prompts and consistent formatting, and tracks metrics like accuracy, conflict rate, and time-to-label.
Use Your Own Model with Custom Logic
You decide how the model should behave by writing a prompt. That prompt can follow specific labeling instructions, reflect project guidelines, or even mirror how your team thinks about annotation. You can even contextualize the model with a golden set for reference.
Once it’s set up, you can call the model from Data Studio whenever needed. It labels all unannotated data in the document, giving you results consistent with your prompt and ready for review.
Models Substituting Labelers
The Labeling Agent treats your model(s) as a project contributor. That means:
- You assign it directly to a project.
- It labels within the app interface.
- Its contributions are visible, trackable, and reviewable.
There’s no need to log in as the model or manage it separately. It works alongside your team, and its output is handled just like human-generated labels.
This empowers you to compare multiple models on the same dataset and quickly visualize agreement levels across annotations. For this test case, we used:
- GPT-4o
- Claude 3.7 Sonnet
- Gemini 2.5 Pro
- LLaMA 3.3 70B
Results
We evaluated each model based on two factors: accuracy and coverage. Accuracy was measured by inter-annotator agreement (IAA) between the model and a human reviewer. Coverage was calculated using the formula:
Each label required agreement with at least 2 models for Datasaur to auto-accept that label: a consensus of 2 out of 4. The remaining labels were reviewed and finalized by a human reviewer.

Using accuracy and coverage, and despite not being the leading LLM for current benchmarks, ChatGPT-4o performed the best of all models.
🔹 Note: Gemini took significantly more time (1h 28m) compared to the other models (8–12 minutes). This may be a tradeoff to consider when optimizing for throughput.
Discussion
These results show that no single model dominates across every metric. ChatGPT achieved the highest overall score: marking an impressive 92% accuracy with zero-shot prompting. Claude offered a balance between speed and quality, where Llama was significantly more efficient with coverage. Gemini provided the best coverage of the dataset but took the longest time to label compared to the group. These insights are important as your team weighs priorities.
If you're experimenting with LLMs for labeling tasks, Datasaur's Labeling Agent makes it easy to compare them side by side. Choose a model, configure your prompt, enjoy hands-free labeling, and start evaluating. Sign up today for access to your Labeling Agent.