English NER vs Global English - A Stanford Research Paper
Stanford University's Department of Computer Science recently undertook a study to assess the effectiveness of English Named Entity Recognition (NER) models. The research primarily examined how these models, which are typically trained on American or British English, perform with different English varieties used globally. This initiative forms part of a larger endeavor to enhance the versatility of NLP technologies.
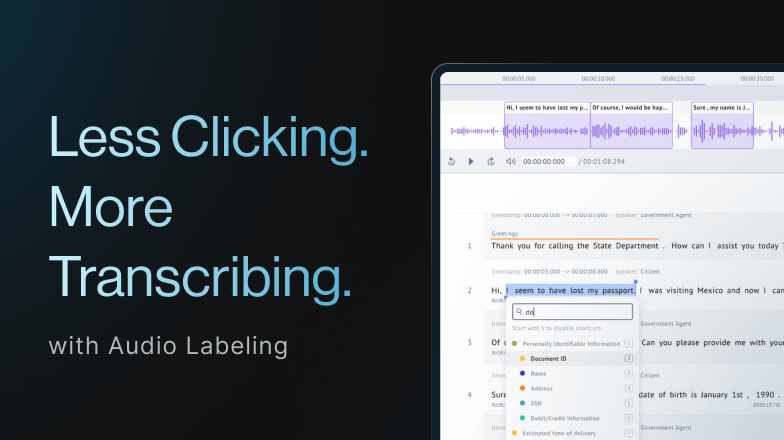
Datasaur contributed its expertise by providing a high-quality annotation platform, complemented by the annotation workforce from MLTwist and Aya Data. A key aspect of the research method was the utilization of our Inter Annotator Agreement (IAA) feature. The labeling quality of all annotators was automatically assessed using Cohen's Kappa coefficient, resulting in an overall score of 77.47, indicative of thorough labeling accuracy.
The study revealed notable disparities in the performance of NER models based on the linguistic variety. The most significant performance drops were observed in datasets from Oceania and Africa, while those from Asia and the Middle East showed relatively strong performance. These findings underscore the importance of incorporating a more inclusive range of linguistic data in training NER models to ensure their effectiveness across a broader spectrum of global English.
For a more detailed report, you can read the full paper here.