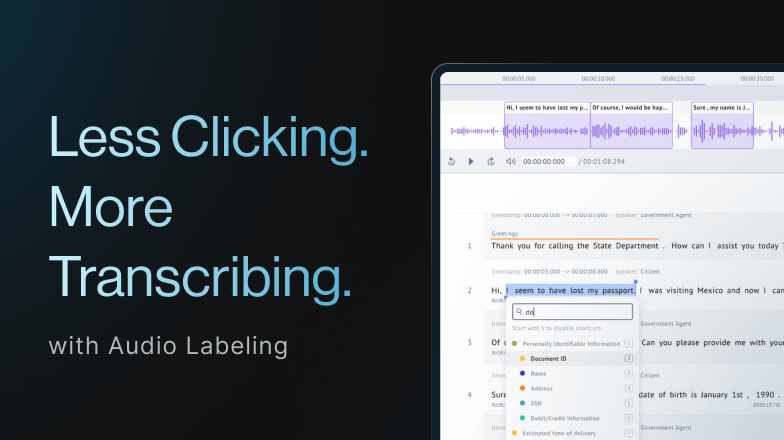
Enhancing Data Quality: Finding and Fixing Label Errors with Datasaur
The data-centric approach in machine learning believes that high-quality datasets are critical and will eventually make or break the model. However, data preparation itself can take up 80% of the allocated resources, emphasizing the need for labeling consistency, data cleansing, and error correction. Driven by the same paradigm, the Datasaur app supports these needs with a labeling system promoting consistency through label consensus and error detection, improving overall dataset quality.
Label Error Detection
We are thrilled to announce Label Error Detection, an innovative feature powered by Metadata Archaeology, designed to identify label errors by tracking model loss during the training process for each individual example.
This technique involves creating two subsets, called probe suites: one for correct labels and one for incorrect labels. By analyzing the training dynamics of the dataset in conjunction with these subsets, we can infer the metadata for each data point, helping us identify whether its label is correct or incorrect.
Case Study
We conducted experiments using Metadata Archaeology on various classification tasks with publicly available datasets: AGnews for news articles, IMDB for movie review sentiment, Yelp_polarity for Yelp review sentiment, and Dbpedia_14 for Wikipedia content classification. To simulate data errors, we sampled the data and altered 10% of the labels, as no specific datasets for this purpose were available. This setup allowed us to evaluate our label error detection's effectiveness using the f1-score metric.
Find more details and insights in our Whitepaper below.
Additionally, if you want to learn how dataset quality affects model performance and how our Label Error Detection can play a part, check out our exploration further below:
The Importance of Data Accuracy and How Label Error Detection Automates QA